
A Courseware Platform for Expressing Pedagogical Intent
Author: Michael Feldstein
Go to Source
In a recent post, I announced a collaboration between Carnegie Mellon University’s (CMU) Open Learning Initiative (OLI) group and Arizona State University’s Center for Education Through eXploration (ETX) to build a next-generation, open-source, open-standards project, which has been facilitated by the Empirical Educator Project (EEP). As I noted in that post, because each group has intra- and extra-university diplomacy and policy responsibilities, I have pre-approved the previous post and this one with ETX and OLI, respectively. With these two posts in place, I will explore some implications in subsequent posts without worrying about coloring outside the lines.
The first post in this series described the nature of the collaboration. This one will describe the nature of the project itself.
A recap of how we got here
Here’s the sequence of events that led to the current project:
First, about a year and a half ago, CMU announced at the EEP summit that they were releasing an open-source collection of over $100 million’s worth of learning engineering software they had developed in a collection they call the OpenSimon Initiative. OpenSimon initially included parts of the OLI’s platform—also called OLI—which is both the original template for most current-generation courseware platforms and a platform designed from the start to support research into applied learning science. (The reasons why they could not initially release all of OLI are unimportant for this story. The resolution of the problem, which I’ll get to momentarily, is more salient.) Norman Bier, who is both the Executive Director of the Simon Initiative and the Director of OLI, spearheaded OpenSimon’s release and has led OLI’s participation in the collaborations to come.
Separately, in the spring of 2019, ETX Director Professor Ariel Anbar decided to fund a courseware interoperability standards effort as part of an Open Educational Resources (OER) development grant the US Department of Education had awarded to the Center (a project which has since been branded OpenSkill). Since ETX planned to develop their OER courses on the proprietary Smart Sparrow platform, Ariel believed that those courses would need to be portable to other platforms to satisfy the spirit of OER. So he hired EEP to help convene a group and facilitate the work. One of the participants that I recommended was OLI. We had a kick-off convening in September of 2019.
Shortly after that convening, Pearson announced that it had acquired the SmartSparrow platform and would be discontinuing support of the product in its current form. (As I noted in my previous post, I have nothing to say about Pearson’s actions other than that ETX stakeholders have told me that the company has worked with the university to make the transition as smooth as possible.) Unfortunately, since we do not yet have courseware interoperability standards, Pearson’s ability to make the transition smooth is limited. There is no easy way to get the functioning courseware out of Smart Sparrow and import it intact into some other one.
Rather than letting this substantial transition derail the interoperability work—ETX has over $15 million’s worth of grant–funded courseware that they need to migrate off of Smart Sparrow by a fixed deadline—Ariel decided his predicament proved that interoperability is too important to ignore. So he began looking for partners who would be willing to invest in this goal.
During roughly this same time period, OLI began developing the next generation of their platform, code-named “Torus,” which could be released as open-source. (The code repository for the project is available on Github today.) After some discussion and exploration, ETX and OLI agreed to be primary partners on this project, developing a specification that would enable ETX’s Smart Sparrow-based experiences to run intact on Torus. They also agreed to design the architecture to use existing interoperability standards whenever possible, propose enhancements to those standards when it is helpful, and to invent non-standard approaches as needed. Torus will be a reference implementation for proposed courseware interoperability standards. It will demonstrate the viability of the proposed standards by showing that it can import and run ETX’s existing Smart Sparrow intact and by enabling ETX to continue authoring Smart Sparrow-style courseware in the future. ETX has engaged EEP to facilitate this collaboration.
A rare opportunity
In this project, we have two different applied academic centers that both build courseware for use at scale. They focus on substantially different (though complementary) research-based course design approaches. Each has chosen a platform because of its suitability for their respective approaches. Both perform efficacy research on the courseware they develop. By bringing them together in this way, we have a rare opportunity to intentionally drive the evolution of the entire product category, starting with a consideration of research-supported pedagogy and driving it deep into the fundamental structure of how courseware platforms are built by influencing their interoperability standards. Technology is the means, not the end. The real goal is to develop a generalized approach for courseware platform architecture that can implement a range of evidence-based design approaches and drive continuous improvement of digital curricular materials that demonstrably support student success and improve equity.
For this reason, I will not be writing about the technical details in this post. Instead, I will focus on foundational pedagogical and functional concepts that drive the design decisions. Readers who are specifically interested in technical interoperability or architectural questions will have to read between the lines. I promise to cover these topics more explicitly in later posts.
Because we have been building toward this public collaboration for quite some time, I have been laying a breadcrumb trail regarding this project since long before I could talk about it explicitly. If you want to really study this project, I recommend reading the other posts that I reference. The links to previous e-Literate posts embedded in this one are more important than usual.
First principles
Let’s start by laying out some basic pedagogical principles that both organizations endorse and that infuse all aspects of plans for this project, from the interoperability standards to the software architecture to the user experience.
First, “to learn” is an active verb. Students cannot “get learned” or “be learned.” They must do the learning themselves.
Learning results from what the student does and thinks, and only from what the student does and thinks. The teacher can advance learning only by influencing the student to learn.
Herb Simon
“Influencing the student to learn” can be interpreted as provoking students to think and do things that you hope will stimulate them to learn. People learn when they try something or think about something and come to a conclusion or insight based on that process of exploration. Part of the craft of teaching is knowing what to give students to think about or try.
The actual learning happens inside a student’s head, which means that it is not directly observable. So another part of teaching is giving students tasks to perform that provide observable clues as to what they may or may not have learned. We call this teaching task “assessment.” Importantly, self-taught learners assess themselves. For example, if I am learning how to make scrambled eggs, I will try to scramble and egg and observe how it comes out. I won’t know if I learned how to make scrambled eggs until I try to scramble one. Likewise, I won’t know if I’ve failed to learn how to scramble an egg. If I assess myself, then I can keep trying things and observing the outcomes until I learn whatever it was that I missed the first time (like, for example, how to tell if the pan is the correct temperature for scrambling an egg). Self-taught learners are, in part, self-assessing learners. They construct tests for themselves to figure out what they haven’t gotten right yet. Educators assist learners with that process.
Regardless of whether I have a cooking coach or if I am teaching myself, I may very well decide what to try next based on the results of my assessment. If my eggs come out poorly, then I will think about what I might have done wrong and try something else. If they came out well, then I might try incorporating them into a breakfast burrito. Or I might move on to learning how to make bacon.
In other words, learning is a feedback loop, where the input is the learning experience and the output is the assessment result. Learning may happen in between the input and the output, inside the black box that is the learner’s head. It may also happen when the learner sees the output, which might become the input for another learning feedback loop. A failed attempt to scramble an egg may cause me to do or think something that enables me to learn how to successfully scramble an egg.
It works something like this:
- Input: I read a recipe for scrambled eggs.
- [Weird things happen in the dark place between my ears.]
- Output: I try to scramble an egg.
- Inference: I judge whether I am ready to move onto making a breakfast burrito or if I have not yet achieved egg-scrambling competency.
(It’s not exactly this clear cut. For example, I learn things about scrambling eggs in the process of scrambling an egg.)
As part of that last step, I’m evaluating whether I’ve learned what I set out to learn. Hence, the feedback loop. Based on that inference I make from the assessment results, I decide whether to repeat the learning feedback loop, adjust it, or move on to a new one. But again, a critical point here is that Step 2—the actual learning—is invisible. The brain is a black box. We only know what goes in and what comes out.
A widely practiced discipline in learning design, known as “backward design,” is built on these fundamental insights. At its simplest, backward design has three steps:
- Specify the desired learning goal or competency (e.g., scrambling an egg)
- Design the assessment that will test progress toward the competency (e.g., trying to scramble an egg)
- Design the experience that will stimulate the learner to do or think something that will hopefully enable them to learn (e.g., reading a recipe)
Steps two and three in backward design correspond to the output and input of the learning process. While step one was implicit in my previous example—I started off wanting to learn how to scramble an egg—it must be explicit when designing a curriculum using this method.
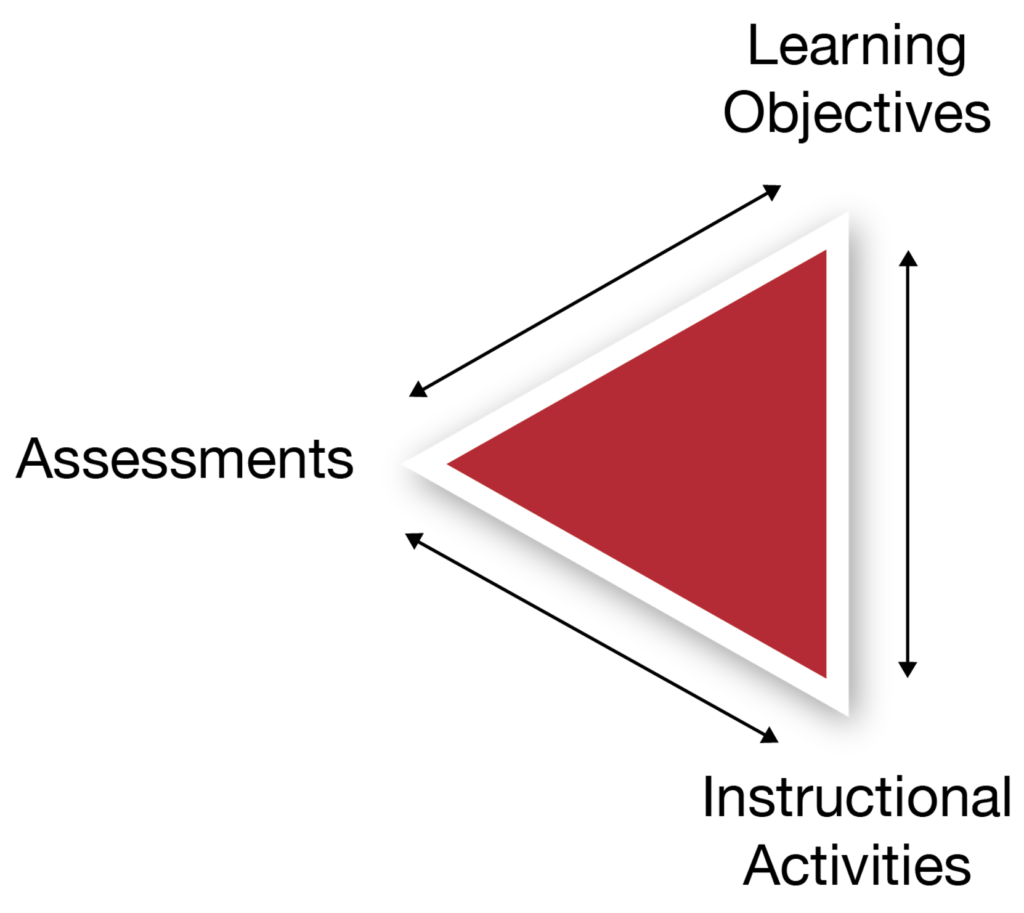
In fact, the curriculum can be thought of as the scope and sequence of these specified learning goals. The scope refers to the full range of competencies that I need to master to reach a larger goal. Is my ultimate aim to learn how to make a bacon-and-egg breakfast or a breakfast burrito? The sequence is the order. I can’t learn how to make a breakfast burrito until I first learn how to scramble an egg. In other words, we can think of the process of learning design—and teaching, and learning—as constructing a series of nested learning feedback loops. Many educators (and learners) construct these loops instinctively and unconsciously, which means that they sometimes miss opportunities to make their designs more effective. But whether consciously or not, all learners, all educators, and all designers of instruction construct sequences of feedback loops. Because without learning feedback loops, there is no learning.
Computers are (mostly) dumber than humans
So humans can’t learn, and therefore can’t teach, without feedback loops. They can’t tell if learning is happening, never mind provoking thought that leads to learning. Guess what? Computers can’t either. And no amount of data or fancy AI algorithms will change that, because both learning and teaching happen via feedback loops. I’ve seen (and written about) a lot of magical thinking in EdTech that talks about data as if it’s fairy dust: one speck is pretty much the same as any other, but the more you have of it, the more magic you get.
I wrote a blog post last December called Pedagogical Intent and Designing for Inquiry which was all about this misconception and how it harms our efforts to build effective EdTech. “Pedagogical intent” should be interpreted as the reasoning behind the design of the learning feedback loop. For example, the software might detect patterns in students’ answers that suggest a particular skill is not being taught well (or at all). Or it might identify a prerequisite skill or bit of knowledge a student missed earlier that is causing her to struggle now.
To find these insights, the computer needs more information about the activities than just the clicks. It needs information about pedagogical intent. Why is the educator assigning the student a particular activity to perform? What was a particular assessment answer choice intended to suggest about the student’s internal mental processes? Without knowing the answers to these questions, the computers are as blind as we are. Here’s an example from that post:
ACT recently released a paper on detecting non-cognitive education-relevant factors like grit and curiosity through LMS activity data logs. This is a really interesting study that I hope to write more about in a separate post in the near future, but for now, I want to focus on how labor-intensive it was to conduct. First author John Whitmer, formerly of Blackboard, is one of the people in the learning analytics community who I turn to first when I need an expert to help me understand the nuances. He’s top-drawer, and he’s particularly good at squeezing blood from a stone in terms of drawing credible and useful insights from LMS data.
Here’s what he and his colleagues had to do in order to draw blood from this particular stone…
First, they had to look at the syllabi. With human eyeballs. Then they had to interview the instructors. You know, humans having conversations with other humans. Then the humans—who had interviewed the other humans in order to annotate the syllabi that they looked at with their human eyeballs—labeled the items being accessed in the LMS with metadata that encoded the pedagogical intent of the instructors. Only after they did all that human work of understanding and encoding pedagogical intent could they usefully apply machine learning algorithms to identify patterns of intent-relevant behavior by the students.
LMSs are often promoted as being “pedagogically neutral.” (And no, I don’t believe that Moodle is any different.) Another way of putting this is that they do not encode pedagogical intent. This means it is devilishly hard to get pedagogically meaningful learning analytics data out of them without additional encoding work of one kind or another.
So far, machine learning has not proven to be generally effective at deducing pedagogical intent based on low-level data like student clicks or time they spend watching a video. It’s getting pretty good at deducing pedagogical intent from data when it is given inputs that are already well-structured to supply hints of that intent. LMS activity logs are not well-structured in this way. Ironically, analog textbook chapters are because they are designed to give humans clues about these things using only text organization, pictures, font styles, and the like. But that doesn’t help us to reliably deduce pedagogical intent in the realm of the digital. There ought to be a better way.
Luckily, there is one.
Learning feedback loops in courseware design
It turns out that virtually every commercial courseware product on the market today, and virtually every course created with substantial input from a professionally trained learning designer, has been built using backward design. Furthermore, most interesting and useful learning analytics in commercial courseware products today get virtually all of their utility from this backward design and very little, if any, from some super-genius artificial intelligence algorithm. Machine learning is most often useful when it can “read” the backward learning design to work its magic. Today’s learning analytics and adaptive learning systems are best thought of as algorithms that attempt to squeeze as much insight and value as possible from the pedagogical intent that has been encoded into the courseware platform in a machine-readable form. They may use other data too. But as the ACT study above illustrates, those other data have limited value when they are disconnected from the context of the learning feedback loop designs and the pedagogical intent behind them.
Last September, I wrote a three-part post series on exactly this topic called “Content as Infrastructure” (the title of which was borrowed from David Wiley). You can probably skip the first post since it covers a lot of the same ground you’ve just read. The second post shows examples of different products that take advantage of backward design to create better educational products, while the third one digs into the various types of insights that can be gained from computers when they have access to semantic information about pedagogical intent. If you want to dig a little deeper, you can go back to my post from 2012 about how CMU’s learning engineering techniques use learning feedback loops to identify hidden prerequisites that the educators may not have realized they need to address (like the recipe writer who doesn’t realize that not all aspiring egg scramblers know how to tell if the pan is the right temperature). Or you can read my post from 2013 about how ETX’s Habitable Worlds course creates experiences that provoke student learning.
Generalizing feedback loops
As promised, I will keep this post non-technical. But given the pedagogical principles above, we can begin to think through the basic requirements for a universal technology design.
First, we need standard ways to describe the smallest and simplest learning feedback loops, like a single multiple-choice question. The student reads the question, chooses an answer, and receives feedback. Simple. And yet, not. A well-written multiple-choice question will have wrong answers—or “distractors,” as they are often (problematically) called—that are intended to diagnose specific common misunderstandings. Students might be given multiple tries on the question, thus traversing the feedback loop multiple times. They might get feedback based on their answer which is intended to help them learn or reinforce their learning. They might be given the option to ask for a hint. Or multiple hints. And each successive hint may be designed to get at a different possible blocker to the student’s learning the correct answer. A single well-design multiple-choice question implemented in a system that gives options for multiple tries, feedback, and hints can be absolutely loaded with pedagogical intent. We want a system that captures as much of that as possible and as automatically as possible. The more that the author’s pedagogical intent can be captured as part of the natural authoring process—rather than requiring the author to add that information afterward—the better.
Second, we need a system that enables learning feedback loops to be connected to each other in different ways, and to create loops within loops. On a fundamental level, if I want to make a bacon-and-egg breakfast, I have to learn how to scramble an egg. If I want to learn how to scramble an egg, I have to learn how to tell if the pan is the right temperature. If I want to learn how to become a short-order cook in a diner, then I need to learn all these skills plus many more.
We also need the feedback loops to be connectable in many ways. A common approach in OLI courses is to give students a string of activities that address the same “learning objective”—a label we attach to a learning goal of a certain granularity that is meaningful in the context of the larger course—and watch to see if the students’ error rates on those problems go down. This requires the ability to tie those problems together in a sequence. A common approach in ETX courses is to create “guided experiential learning” exercises, in which students learn by exploring. This requires the ability to branch students to different learning feedback loops based on their answer to the previous one (even if the branch is just a short detour that leads back to the main path). Both approaches are valid and not mutually exclusive. They can be used in the same course. Sometimes they can even be incorporated into the same exercise.
When we talk about interoperability—which was where this project started—we can mean at least two very different and equally important goals. The first is to be able to export a learning feedback loop design of any grain size—a multiple-choice question, a quiz, a loop that addresses a skill, or a learning objective, or a competency, or a lesson, a course, a certificate program, etc. (You might be surprised at the amount of thought that goes into designing a single multiple-choice question to create a truly diagnostic learning feedback loop.)
The generic word we use for a compound learning loop of any size is an “ensemble.” I’ve seen a lot of debate and hand-wringing over the years about what a “learning object” is, how big or small one can be, and so on. The problem with “object” is that it’s a fancy name for “thing.” Of course very different kinds of learning things should be very different sizes. In this project, we talk about learning feedback loops, which also can be very different sizes. But they are all the same basic type of thing, in the sense that they have learning inputs and produce learner outputs which are diagnostic of particular learning goals. Any learning thing—whether it is a picture or a course unit or something else—which does not have these characteristics is not a learning feedback loop.
We should be able to move the content, the execution logic of the learning loops, and the encoding of the pedagogical intent, intact, from one system to another. We also should be able to analyze student activities in the context of the pedagogical intent of the learning loop the same way for any courseware in any system. We should be able to know what the learning goal is, what the student’s assessment answer suggests about progress toward that goal, and so on. The interoperability project aspires to achieve both of these goals, although they will take some time to refine and to take them through an official standards-making process.
And we want to create a system that encourages educators to author learning feedback loops that are well-crafted and continuously improve that content based on feedback from the system on how well it is helping the students. Most educators—particularly ones who have no formal training in education, like the vast majority of college professors—do not naturally think about what they are doing as crafting series of learning feedback loops. Even when they understand the basic idea, they may not have all the skills that could help them (just as understanding the basic concept of scrambling an egg does not automatically convey the skill of making yummy scrambled eggs). For example, a learning designer recently told me that some of the professors she works with don’t know that they should try to write multiple-choice distractors designed to diagnose specific misconceptions. In an ideal world, a courseware platform would have an authoring interface, analytics, and nudges that all encourage courseware designers—whether they are first-time amateurs or skilled professionals—to constantly be working to test and refine their learning feedback loops.
This thing is real
These are obviously big ambitions that will take a long time to realize. Some of them will take at least few years to get right or to get through formal standards-making processes. That said, this is more than just another grand idea that will probably never happen.
It is happening right now.
Here are some milestones that the collaboration has achieved so far:
- Torus exists. The source code is available. Some simple courses are in production on a stable version of it.
- OLI had several teams build sample lessons on Torus during a virtual summer school program.
- ETX, with the help of Unicon’s architects and developers, has exported the lessons from Smart Sparrow, including the logic of the learning loop design.
- Unicon has built several iterations of a harness that can run a wide range of ETX Smart Sparrow with increasing fidelity. To be clear, they are not rebuilding these lessons. They are running the exported lessons, with the full learning experience, intact.
- The collaboration team has demonstrated the ability to launch the ETX lessons from OLI.
- IMS Global, one of the major technical interoperability standards bodies for education, has been kept apprised of the work and has been actively supportive of it.
- Unicon’s latest iteration of the Smart Sparrow test harness runs the full representative sample of ETX lessons with production-quality fidelity. (A few minor tweaks remain to be completed.)
Here are some planned milestones:
- The collaboration team is in the process of generalizing the runtime commands for the ETX learning loops into a specification that can be implemented in Torus and submitted as a formal interoperability specification candidate.
- In parallel, ETX and Unicon are working on a developer’s aid that will enable ETX experts to begin creating new ETX-style lessons in the first quarter of 2021. While it will not be suitable for general use, it will help us continue to refine the specification and think about broader authoring requirements.
- By the fall of 2021, ETX expects to migrate all of its Sparrow courses onto Torus and OLI expects to put a substantial subset of its courses into production on Torus.
- Work on enriching the authoring interface will proceed in parallel, with the goal of releasing an authoring solution that fully supports multiple styles of course design by January of 2022.
- OLI will complete its migration of all its courses to Torus by the fall of 2022. Given the current size and growth of the two projects, I expect the combined annual enrollments on the platform to be well north of 150,000 – 200,000 at a minimum at that time.
The progress and productivity of this collaboration has been amazing. I’ve never seen anything like it in my entire career. And the architectural innovations are quite clever. I can’t wait to start writing about them.
But the main take-away for now should be that this project is real, it is already producing tangible results, and it will be out in the world in a meaningful way within a year.
Some of you have already asked me if you can observe or even participate in this project. We are thinking about ways to do that and will have some answers for you in the new year. There will likely be several options, depending on the nature and seriousness of your interest. Opportunities for observation will likely come before we can open up for participation, particularly given the aggressive deadlines that both ETX and OLI have to meet. But this is a public good project with a core commitment to openness. If you are interested in getting involved, please contact me. I’m gathering information about interest so that we can begin planning a community strategy.
Stay tuned for more
This post barely scratches the surface of the ambition. In future posts, I will be digging deeper into the details. In the meantime, I suggest again that you (re)read the second and third installments of my Content as Infrastructure post series to get a little more grounding in how much work the basic structures I’ve described here can accomplish and my post Pedagogical Intent and Designing for Inquiry regarding why capturing pedagogical intent is so important for gaining insights on teaching and learning out of these systems.
The post A Courseware Platform for Expressing Pedagogical Intent appeared first on e-Literate.