Pedagogical Intent and Designing for Inquiry
Author: Michael Feldstein
Go to Source
I’ve been asked by several folks to write up some version of the talk I gave at the recent IMS learning analytics summit. The focus was on how, going forward, interoperability standards will need to capture pedagogical intent if we are going to develop meaningful learning analytics.
This isn’t a word-for-word transcription of that talk, but it does capture the gist. The subtitles and literary quotes are mostly from the original presentation. Many thanks to Rob Abel and Cary Brown for inviting me and giving me the opportunity to speak to the IMS community about this important inflection point.
Interoperability is communication
We are not here to curse the darkness, but to light the candle that can guide us through that darkness to a safe and sane future.
John F. Kennedy
Ten or fifteen years ago, when we talked about what we wanted from EdTech software interoperability, most of the time the things we wanted seemed like they ought to be simple. Mostly, we just wanted to transfer student roster and grade information from one system to another. When we got a little more ambitious, we asked for single sign-on and the ability to put a little window of one application into another one. This was foundational interoperability. It wasn’t “disruptive” or “revolutionary” or otherwise life-altering, but it was important.
My first close encounter with an IMS interoperability effort was when I worked at Oracle in on Peoplesoft Campus Solutions team. We just wanted to be able to send a course roster to the LMS and have the LMS send a final grade for each student back. Going in, I couldn’t understand why that was hard or why it hadn’t already been done. All I knew was that (a) it was a problem that IMS had tried and failed to solve at least once before, since we were working on the revision of an existing standard, and (b) a consequence of that failure was that IT professionals on campuses everywhere had to cook up their own, often time-intensive, duct-tape-and-chewing-gum solutions to getting roster data into the LMS. As for grades, it made no sense to me that faculty had to copy grades from their electronic LMS grade book and manually re-enter them into their electronic SIS grade book. It seemed weird that this was a thing.
It turned out that there was a translation problem. Registrars think about classes very differently than instructors and students do. For a registrar, if a student is taking a “statistics for psychology majors” course, and that course can be taken for credit in either the psychology or the math department, then “statistics for psychology” is actually two completely separate courses. And the decision of which of the two courses a student registers for may make the difference between that student meeting the requirements for graduation or not. On the other hand, the students and instructor experience “statistics for psychology” as one course meeting in one place on one schedule with one syllabus and one group of people.
Good software reflects and supports the needs and expectations of its users. Accordingly, SIS software represented “statistics for psychology” as two courses, while LMS software wanted to create one course space for it. In order to have roster information show up as instructors and students expect it in the LMS and then return final grades as the registrar expects them in the SIS, the standards committee had to recognize that there was a translation problem and design a specification that could function as a two-way translator.
This was an important lesson for me. Even seemingly simple interoperability challenges can be complicated because they often aren’t about the software so much as they are about the people who use the software. Interoperability design is at least partly a liberal art.
Now, today, we would have a different possible way of solving that particular interoperability problem than the one we came up with over a decade ago. We could take a large data set of roster information exported from the SIS, both before and after the IT professionals massaged it for import into the LMS, and aim a machine learning algorithm at it. We then could use that algorithm as a translator. Could we solve such an interoperability problem this way? I think that we probably could. I would have been a weaker product manager had we done it that way, because I wouldn’t have gone through the learning experience that resulted from the conversations we had to develop the specification. As a general principle, I think we need to be wary of machine learning applications in which the machines are the only ones doing the learning. That said, we could have probably solved such a problem this way and might have been able to do it in a lot less time than it took for the humans to work it out.
I will argue that today’s EdTech interoperability challenges are different. That if we want to design interoperability for the purposes of insight into the teaching and learning process, then we cannot simply use clever algorithms to magically draw insights from the data, like a dehumidifier extracting water from thin air. Because the water isn’t there to be extracted. The insights we seek will not be anywhere in the data unless we make a conscious effort to put them there through design of our applications. In order to get real teaching and learning insights, we need to understand the intent of the students. And in order to understand that, we need insight into the learning design. We need to understand pedagogical intent.
That new need, in turn, will require new approaches in interoperability standards-making. As hard as the challenges of the last decade have been, the challenges of the next one are much harder. They will require different people at the table having different conversations.
Data and communication are not the same
O wonder!
How many goodly creatures are there here!
How beauteous mankind is! O brave new world
That has such people in’t!William Shakespeare
The quote above is from The Tempest. Here’s the scene: Miranda, the speaker, is a young woman who has lived her entire life on an island with nobody but her father and a strange creature who she may think of as a brother, a friend, or a pet. One day, a ship becomes grounded on the shore of the island. And out of it comes, literally, a handsome prince, followed by a collection of strange (and presumably virile) sailors. It is this sight that prompts Miranda’s exclamation.
As with much of Shakespeare, there are multiple possible interpretations of her words, at least one of which is off-color. Miranda could be commenting on the hunka hunka manhood walking toward her.
“How beauteous mankind is!”
Or. She could be commenting on how her entire world has just shifted on its axis. Until that moment, she knew of only two other people in all of existence, each of who she had known her entire life and with each of whom she had a relationship that she understood so well that she took it for granted. Suddenly, there was literally a whole world of possible people and possible relationships that she had never considered before that moment.
“O brave new world / That has such people in’t”
So what is on Miranda’s mind when she speaks these lines? Is it lust? Wonder? Some combination of the two? Something else?
The text alone cannot tell us. The meaning is underdetermined by the data. Only with the metadata supplied by the actor (or the reader) can we arrive at a useful interpretation. That generative ambiguity is one of the aspects of Shakespeare’s work that makes it art.
But Miranda is a fictional character. There is no fact of the matter about what she is thinking. When we are trying to understand the mental state of a real-life human learner, then making up our own answer because the data are not dispositive is not OK. As educators, we have a moral responsibility to understand a real-life Miranda having a real-life learning experience so that we can support her on her journey.
Intention matters in education
With regard to moral rules, the child submits more or less completely in intention to the rules laid down for him, but these, remaining, as it were, external to the subject’s conscience, do not really transform his conduct.
Jean Piaget
The challenge that we face as educators is that learning, which happens completely inside the heads of the learners, is invisible. We can not observe it directly. Accordingly, there are no direct constructs that represent it in the data. This isn’t a data science problem. It’s an education problem. The learning that is or isn’t happening in the students’ heads is invisible even in a face-to-face classroom. And the indirect traces we see of it are often highly ambiguous. Did the student correctly solve the physics problem because she understands the forces involved? Because she memorized a formula and recognized a situation in which it should be applied? Because she guessed right? The instructor can’t know the answer to this question unless she has designed a series of assessments that can disambiguate the student’s internal mental state.
In turn, if we want to find traces of the student’s learning (or lack thereof) in the data, we must understand the instructor’s pedagogical intent that motivates her learning design. What competency is the assessment question that the student answered incorrectly intended to assess? Is the question intended to be a formative assessment? Or summative? If it’s formative, is it a pre-test, where the instructor is trying to discover what the student knows before the lesson begins? Is it a check for understanding? A learn-by-doing exercise? Or maybe something that’s a little more complex to define because it’s embedded in a simulation? The answers to these questions can radically change the meaning we assign to a student’s incorrect answer to the assessment question. We can’t fully and confidently interpret what her answer means in terms of her learning progress without understanding the pedagogical intent of the assessment design.
But it’s very easy to pretend that we understand what the students’ answers mean. I could have chosen any one of many Shakespeare quotes to open this section, but the one I picked happens to be the very one from which Aldous Huxley derived the title of his dystopian novel Brave New World. In that story, intent was flattened through drugs, peer pressure, and conditioning. It was reduced to a small set of possible reactions that were useful in running the machine of society. Miranda’s words appear in the book in a bitterly ironic fashion from the mouth of the character John, a “savage” who has grown up outside of societal conditioning.
We can easily develop “analytics” that tell us whether students consistently answer assessment questions correctly. And we can pretend that “correct answer analytics” are equivalent to “learning analytics.” But they are not. If our educational technology is going to enable rich and authentic vision of learning rather than a dystopian reductivist parody of it, then our learning analytics must capture the nuances of pedagogical intent rather than flattening it.
This is hard.
Some more examples
The lesson assessment example is easy enough to understand. (My post series on content as infrastructure explores it in more detail.) But the more one looks around at the full range of analytics that are truly aimed at supporting student success, the clearer the lesson about capturing intent becomes.
Take, for example, summer melt. I recently just hosted an entire hour-long Standard of Proof webinar on this topic. (You should watch it. It’s good.) Here’s a slide from that webinar which illustrates the obstacles that first-generation students face in getting from their college acceptance letter to the first day of class:
The Summer Melt Maze
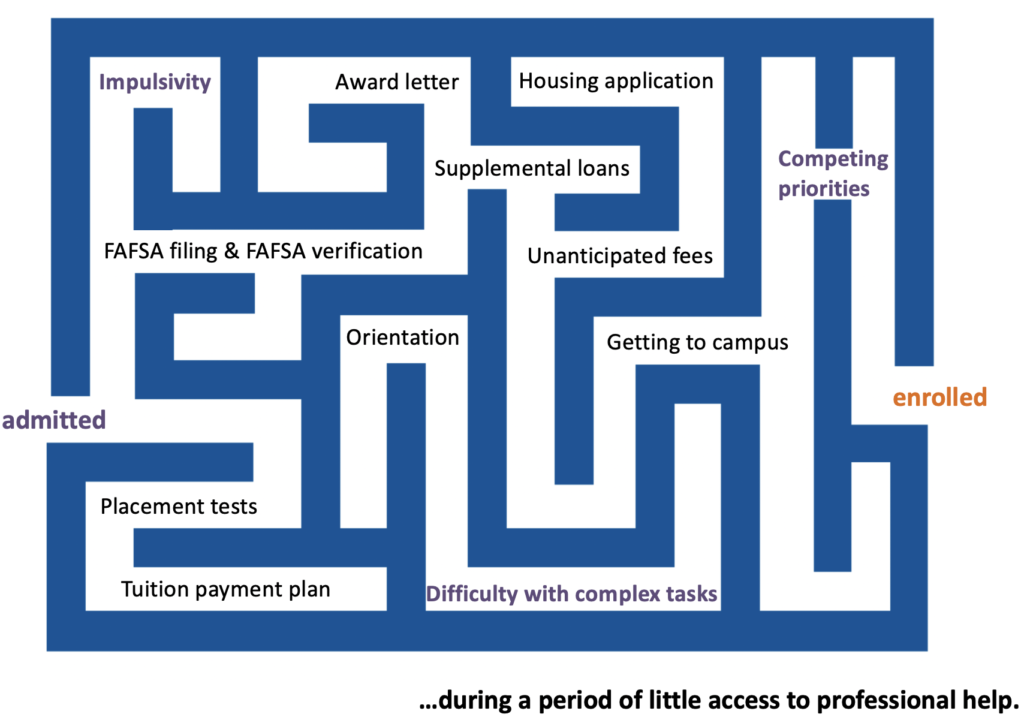
Each of the text labels represents an obstacle that first-generation students in particular may struggle to overcome, because their circumstances are complex (e.g., no parent to provide a parental signature), because they don’t have parents or guardians who have the training and knowledge to help them, and/or because they’re seventeen-year-old kids. I don’t know about you, but I don’t think I had to navigate a single one of these obstacles without parental help, and I don’t know if I could or would have done so without it.
Now think about developing a software solution to identify the specific barrier a student is struggling with and provide appropriate help. Could you solve the problem simply by sucking in enough data and running a machine learning algorithm? I very much doubt it. And even if you could, think about how invasive you would have to be to do so. Think about the privacy implications. The cure would be worse than the disease.
Georgia State University took a different approach. They have invited students to share their intent. They use a chatbot. A chatbot is a conversational interface. Students can ask directly about the problems they were encountering. Once students specify their intent, then machine learning can be used to further disambiguate it. For example, the software can figure out that a student who writes “I have no money” may be asking for help obtaining financial aid. But only because there is a conversational interface, and because the software behind that interface has been programmed to anticipate and respond to a certain range of questions that a student might come to the chatbot for answers. Through a combination of the interface layer, the data layer, and the usage context, the educational intent was encoded into the system.
Here’s another example that postdates my talk. ACT recently released a paper on detecting non-cognitive education-relevant factors like grit and curiosity through LMS activity data logs. This is a really interesting study that I hope to write more about in a separate post in the near future, but for now, I want to focus on how labor-intensive it was to conduct. First author John Whitmer, formerly of Blackboard, is one of the people in the learning analytics community who I turn to first when I need an expert to help me understand the nuances. He’s top-drawer, and he’s particularly good at squeezing blood from a stone in terms of drawing credible and useful insights from LMS data.
Here’s what he and his colleagues had to do in order to draw blood from this particular stone:
The online interaction features were generated from the LMS clickstream data. After manual inspection, we determined that the action field alone (e.g., “opened”) was insufficient to address our research questions and needed to be joined with the label of the item that the action was taken in reference to, which was a complex pairing. For example, course item values in the LMS data include “Week 12: Electrochemistry” or “CHEM 102 Practice Exam 4B,” which were easily interpretable from the course syllabus, while others (e.g., “2/27 CL” or “18.7 RQ”) required confirmation from the instructor. Hence, we created broader activity categories for these activity events in the LMS data using the course syllabus with confirmation from the instructor which resulted in 110 unique activity events in the LMS data that were recoded to a total of 21 activity categories as described in Table 4.
First, they had to look at the syllabi. With human eyeballs. Then they had to interview the instructors. You know, humans having conversations with other humans. Then the humans—who had interviewed the other humans in order to annotate the syllabi that they looked at with their human eyeballs—labeled the items being accessed in the LMS with metadata that encoded the pedagogical intent of the instructors. Only after they did all that human work of understanding and encoding pedagogical intent could they usefully apply machine learning algorithms to identify patterns of intent-relevant behavior by the students.
LMSs are often promoted as being “pedagogically neutral.” (And no, I don’t believe that Moodle is any different.) Another way of putting this is that they do not encode pedagogical intent. This means it is devilishly hard to get pedagogically meaningful learning analytics data out of them without additional encoding work of one kind or another.
Interoperability without intent creates chaos
If Jorge Luis Borges’ Library of Babel could have existed in reality, it would have been something like the Long Room of Trinity College.
Christopher de Hamel
I want to underscore the point that there simply collecting more data and writing more clever algorithms will not help us find a way out of the problem of that last example. It is a problem of epistemic closure. Data and knowledge are not the same, and more data do not necessarily unlock more knowledge.
“The Library of Babel” is a short story by the great Jorge Luis Borges. (It’s only nine pages long. You should read it.) The story describes a world that perfectly captures the nature of the problem we face:
The universe (which others call the Library) is composed of an indefinite and perhaps infinite number of hexagonal galleries, with vast air shafts between, surrounded by very low railings. From any of the hexagons one can see, interminably, the upper and lower floors. The distribution of the galleries is invariable. Twenty shelves, five long shelves per side, cover all the sides except two; their height, which is the distance from floor to ceiling, scarcely exceeds that of a normal bookcase. One of the free sides leads to a narrow hallway which opens onto another gallery, identical to the first and to all the rest. To the left and right of the hallway there are two very small closets. In the first, one may sleep standing up; in the other, satisfy one’s fecal necessities. Also through here passes a spiral stairway, which sinks abysmally and soars upwards to remote distances….
There are five shelves for each of the hexagon’s walls; each shelf contains thirty-five books of uniform format; each book is of four hundred and ten pages; each page, of forty lines, each line, of some eighty letters which are black in color. There are also letters on the spine of each book; these letters do not indicate or prefigure what the pages will say….
The orthographical symbols are twenty-five in number. This finding made it possible, three hundred years ago, to formulate a general theory of the Library and solve satisfactorily the problem which no conjecture had deciphered: the formless and chaotic nature of almost all the books. One which my father saw in a hexagon on circuit fifteen ninety-four was made up of the letters MCV, perversely repeated from the first line to the last. Another (very much consulted in this area) is a mere labyrinth of letters, but the next-to-last page says Oh time thy pyramids. This much is already known: for every sensible line of straightforward statement, there are leagues of senseless cacophonies, verbal jumbles and incoherences….
Five hundred years ago, the chief of an upper hexagon came upon a book as confusing as the others, but which had nearly two pages of homogeneous ines. He showed his find to a wandering decoder who told him the lines were written in Portuguese; others said they were Yiddish. Within a century, the language was established: a Samoyedic Lithuanian dialect of Guarani, with classical Arabian inflections. The content was also deciphered: some notions of combinative analysis, illustrated with examples of variations with unlimited repetition. These examples made it possible for a librarian of genius to discover the fundamental law of the Library. This thinker observed that all the books, no matter how diverse they might be, are made up of the same elements: the space, the period, the comma, the twenty-two letters of the alphabet. He also alleged a fact which travelers have confirmed: In the vast Library there are no two identical books. From these two incontrovertible premises he deduced that the Library is total and that its shelves register all the possible combinations of the twenty-odd orthographical symbols (a number which, though extremely vast, is not infinite): Everything: the minutely detailed history of the future, the archangels’ autobiographies, the faithful catalogues of the Library, thousands and thousands of false catalogues, the demonstration of the fallacy of those catalogues, the demonstration of the fallacy of the true catalogue, the Gnostic gospel of Basilides, the commentary on that gospel, the commentary on the commentary on that gospel, the true story of your death, the translation of every book in all languages, the interpolations of every book in all books.
Jorge Luis Borges
The rest of the story is a rumination on how humans might make sense of this infinite series of rooms—this “data lake,” in modern parlance—in absence of any information about the intent of its creator.
Since the Library contains every possible book with that number of pages, lines and characters, somewhere in all these rooms must exist a book that explains exactly what it all means. So it’s a data search problem, right?
Wrong. Because there also exist books that are extremely similar but differ in minor but critical details. And books that argue why the book with the Truth is actually false. For that matter, there are books that contain many of the exact same words in the exact same order but are written in languages in which the words mean different things. How can one tell which account is the Truth?
One can’t.
If we are going to make progress toward educationally useful analytics, then we must ruthlessly expunge all traces of magical thinking about data. There are fundamental limits to what the data can tell us. Even systems that are designed for pedagogical intent do not necessarily encode it in a way that is useful for interoperable analytics. In some cases, it may be encoded at the user interface layer. A courseware authoring platform may never label an assessment as “formative” or “summative” in the data because the intended distinction is obvious to the users. In other cases, the data may be encoded in an idiosyncratic manner that does not map well to other systems (either of software or of thought). In still other cases, it may be designed badly and incorrectly or misleadingly reflect the pedagogical intent. It would be relatively easy to create a data lake of Babel which we could explore infinitely in a fruitless search for meaning.
That way lies madness.
If we want useful educational analytics, then we cannot simply worship the data and the algorithms. The humans must do some of the learning.
The “semantic web” is all about intent
I love you. You are the object of my affection and the object of my sentence.
Mignon Fogarty
One of the triggers for my being invited to speak at IMS about learning analytics in the first place was a previous post I wrote which was (partly) on how the structure of Caliper, which is borrowed from the structure of the semantic web, supports new sorts of interoperability conversations. Since you can read that blog post, I won’t repeat the argument in detail here. But the gist is that we both have to and can boil down chains of inference that combine pedagogical intent into simple human language that educators can understand and articulate for themselves. The triple structure of the semantic web—a simple three-word sentence with a subject, a verb, and a direct object—is designed to enable non-technical humans to string thoughts and inferences together in ways that enable more technical humans to translate those inference patterns into data structures and interoperability requirements.
Right now, IMS Caliper adopters are largely using this vernacular as just one more IT tool for largely old-school data centralization. So now they use a “lake” instead of a “warehouse.” It’s still a centralized and IT-specialized mindset which is not suited for thinking about making meaning from multiple applications, never mind talking with other humans about interpreting the intent of users working across multiple applications.
This is the problem that must be solved over the next decade to make real progress on educational analytics. It is at least partly a liberal arts problem. And it will be at least a decade’s worth of work, though we don’t have to wait that long to see early results.
You get to choose the world we live in
O wonder!
How many goodly creatures are there here!
How beauteous mankind is! O brave new world
That has such people in’t!Shakespeare or Huxley?
So which will it be? A brave new world in which we experience continuous wonder at how beauteous mankind is, or one in which “learning” is defined by the ability to correctly answer a series of questions and earn some digital badges? The difference between these possible futures is not one in which we embrace or reject technology, or data. It’s one in which we either embrace or ignore the complexity of human learning and the reality that we must make a conscious effort to ensure that some of this complexity is encoded into the data if we are going to design analytics systems that are educationally useful. We need to elicit specific reactions from our students as expert educators and encode the pedagogical intent for eliciting those reactions along with the reactions themselves.
.The play’s the thing!
William Shakespeare
The post Pedagogical Intent and Designing for Inquiry appeared first on e-Literate.